在認知主義中,可以區分兩種潮流。第一個稱為人類信息處理 (HIP)。這種電流的靈感來自控制論。具體來說,它基於人類大腦的作與計算機執行的數據處理過程之間的類比。
HIP 分析認知過程的作,例如記憶、思維、語言、運動和感知。在這篇文章中,我們將一起深入研究資訊處理理論。
什麼是資訊處理理論
人類信息處理並不是真正的認知發展理論,而是一種將大腦與適用於各種認知過程(如記憶、思想、語言、運動和感知)的計算機處理刺激進行比較的方法.這種方法側重於績效(而不是競爭),將變化視為定量(而不是定性),並且對過程如何展開(而不是展開的內容)感興趣。
信息處理理論的背景
HIP 在 1960 年代提出的第一個心理功能模型的特點是對資訊的嚴格串行處理以及處理作和選擇階段序列中的最終位置。
這些模型提供了有限的信息處理能力和自主處理管道。這些 「pipeline」 模型的優點在於它們的簡單性。然而,實驗數據並不總是證實它們的有效性。
自 1970 年代以來,出現了「級聯」或「並行」模型,它們通過通信管道提供同步資訊處理 ,並且選擇作位於資訊處理過程的早期階段。這些模型意味著無限的處理能力、不同級別資訊處理之間交互的可能性以及替代策略的使用。
雖然結構管道模型假設存在資訊處理作的“塊”,但後者是功能性的,因為它們首先意味著執行不同作的資訊流。
信息處理理論的作者
誰創造了資訊處理理論?此類研究的名稱來源於Peter H. Lindsay和 Donald A. Norman 於 1972 年撰寫的書名「人類資訊處理:心理學導論」,但該理論的基礎必須從認知主義的黎明開始尋找。讓我們看看資訊處理理論的所有作者:
- 奈瑟,認知主義之父。他提出了 HIP 模型,將人類思維視為信息處理器。
- 系列模型是 60 年代提出的心理功能模型。其中最著名的是 Richard Chatam Atkinson 和 Richard Shiffrin 於 1968 年提出的多商店或模式模型。
- 從 1970 年代開始出現的連續「級聯」和「並行」模型提供了通過通信渠道同時處理資訊。自 1970 年代以來出現的“瀑布”模型的一個例子是 Max Coltheart、Brent Edward Curtis、Paul Atkins 和 Michael Haller 的“雙路徑瀑布模型”。
- 另一方面,“並行”模型的一個例子是“並行分散式處理”(PDP),由於心理學家 David Rumelhart 和 James Mcclelland 的研究,它在 1980 年代開始流行。
信息處理理論的特點
在談論加工理論的特點時,應該強調不同的元素:
- 這是一種心理學理論,將人視為信息處理器,並使用計算機作為人類思維運作的模型。人類被明確視為信息的處理者。
- 認知系統被視為所謂的「馮·諾依曼機」類型的計算機,該系統具有理論上可以擴展到無限的記憶體,以及稱為中央處理單元 (CPU) 的中央處理單元。
- HIP 範式的中心假設是,在刺激和反應之間插入了一系列稱為細化階段的心理作,這些作是根據刺激傳遞的信息發展起來的。這些作中的每一個都需要一定的時間來開發,但如果資訊不是在每個階段都生成,那麼在接下來的階段中將不可用。
- 範式有兩種結構:功能和結構。後者定義或描述給定階段中信息的性質。首先是執行的作。
信息處理理論的例子
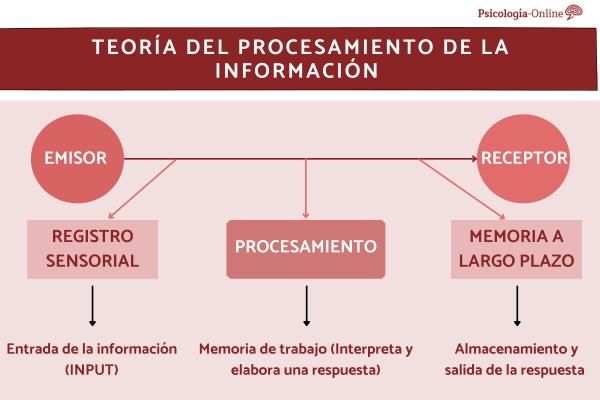
根據第一個 HIP 理論,為了在人類系統中處理資訊,它必須通過連續階段完成,而不是並行完成。每個階段需要幾毫秒。處理基於將獲取的資訊與新資訊進行比較。讓我們看看通過記憶功能進行資訊處理的理論示例:
- 現象學現實以能量的形式提供了一系列刺激(輸入),這些刺激(輸入)可以被感知系統識別和轉化。刺激檢測器只不過是神經細胞。例如,旋律的聲音或香水的氣味。
- 所有輸入和輸出資訊都存儲在一個小的短期記憶體中,該記憶體儲存的資訊很少,但速度非常快。那個聲音或氣味暫時存儲在短期記憶中。
- 檢測到刺激的細胞被啟動並從工作記憶中提取資訊,將其與長期記憶進行比較並允許識別。繼續執行這些範例,系統查看它是否包含有關相關聲音或氣味的資訊。如果是這樣,那就意味著它有錢購買它們並將承認它們。
- 長期記憶體包含無限數量的快速編譯數據存儲,這與短記憶體不同,短記憶體的處理速度相當慢。
本文僅供參考,我們無權做出診斷或推薦治療方法。我們邀請您去看心理學家來治療您的特定情況。





